Optimizer Research & Progress
Muon1, a SOTA-level optimizer, takes a new approach toward optimization. By analyzing and hypothesizing how its mechanics work, one can try to design a similar optimizer from the same core ideas. Since Muon orthogonalizes 2D update matrices using Newton-Schulz iterations, it is naturally connected to the Stiefel manifold: the space of matrices with orthonormal columns.
$$
\mathrm{St}(n, k) = { X \in \mathbb{R}^{n \times k} : X^\top X = I_k }
$$
So rather than treating Muon as only a clever normalization trick, I viewed it as an optimizer whose strength may come from enforcing useful manifold-like geometry on the update. From there, I decided to try improving the efficiency of Muon with a manifold-based optimizer, keeping only the mechanics I believed were most essential and seeing how close the performance could get.
The research is very much ongoing so for this post I would just like to share the results so far. Running on modded-nanogpt2 with 2B tokens on a dual RTX 5090 rig, I achieved close results:
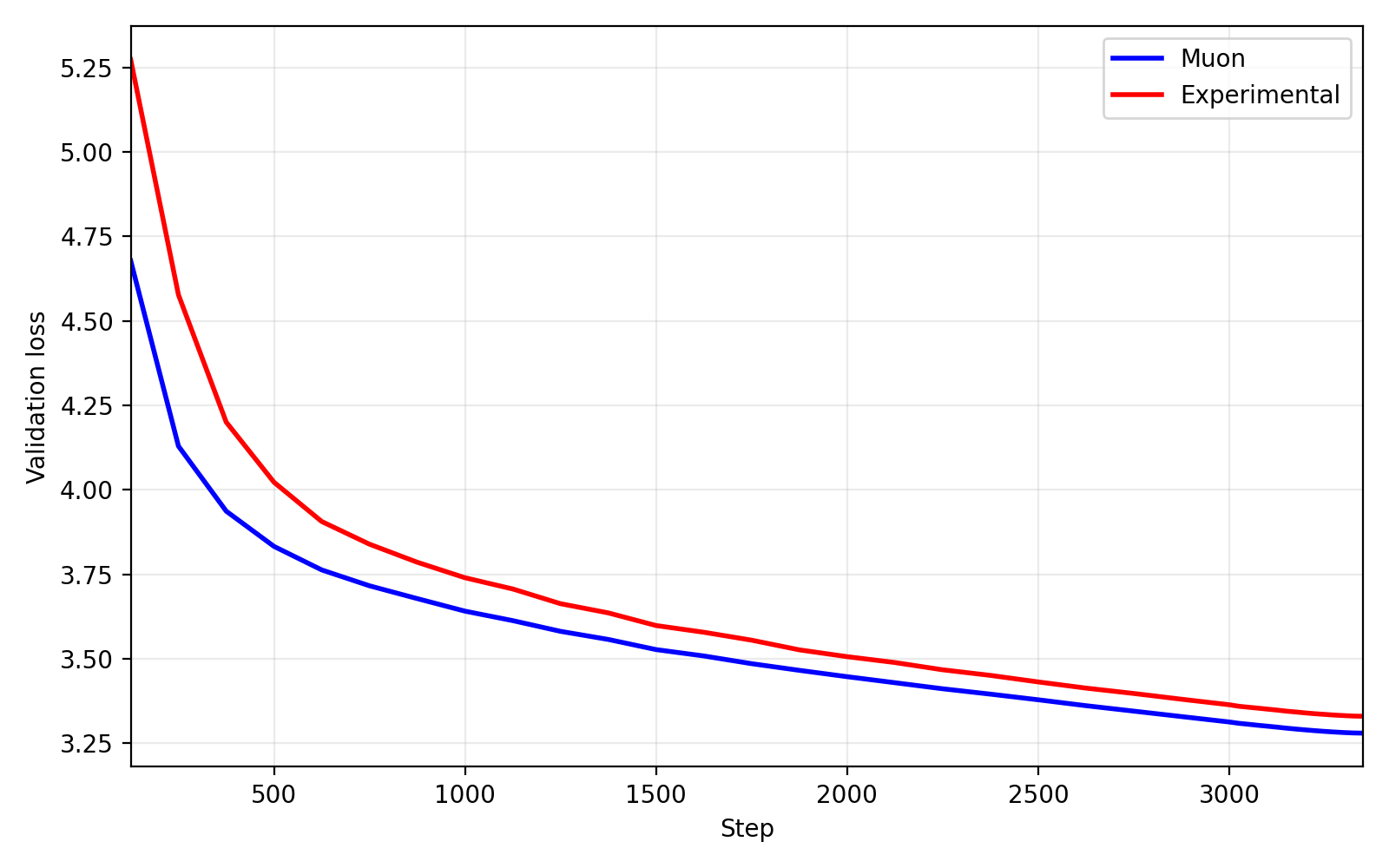
Final results at step 3350:
$$
\text{Muon}=3.28010, \text{ Experimental}=3.33010 \Rightarrow \Delta\approx0.05
$$
With the delta being just $0.05$ the optimizer is quite close to muon! You might be wondering "well Muon still outperforms your optimizer why does this matter?" The default implementation of Muon in the modded-nanogpt optimizer track computes roughly $25$ matmuls, and my optimizer achieves those results with roughly $3$! This is a $8.\bar{3}\times$ theoretical efficiency gain!
Tuning was done with a custom configured autoresearch3, and although $3.330$ is not my best result, it is the simplest version of the optimizer with the best relative score, so I consider it more competitive.
I am still attempting to improve the optimizer performance, I don't think this is impossible, the descent is good, but the issue seems to lie in update geometry. Evidence to support this is using SVD supplementally on the update gives a validation loss of $3.300$ at step $3350$ a $0.03$ improvement bringing the delta from Muon from $0.05\rightarrow 0.02$, but this is $2\times$ more expensive wall-clock time wise.
I will publish a blog when the research is done explaining the optimizer, and possibly a separate article about my process of designing it.
-
Keller Jordan, Dec 8th 2024, Muon: An optimizer for hidden layers in neural networks. ↩
-
Keller Jordan, 2026, Modded-NanoGPT Optimization Benchmark. ↩
-
Andrej Karpathy, 2026, autoresearch. ↩